Live Log Analyzer
by Eliot http://www.saltycrane.com/blog/
2010-06-17
This presentation is an HTML5 website (copied from http://ihumanable.com/jquery/presentation.html)
Use right arrow key to advance, ctrl +/- to zoom
Source code: http://github.com/saltycrane/live-log-analyzer
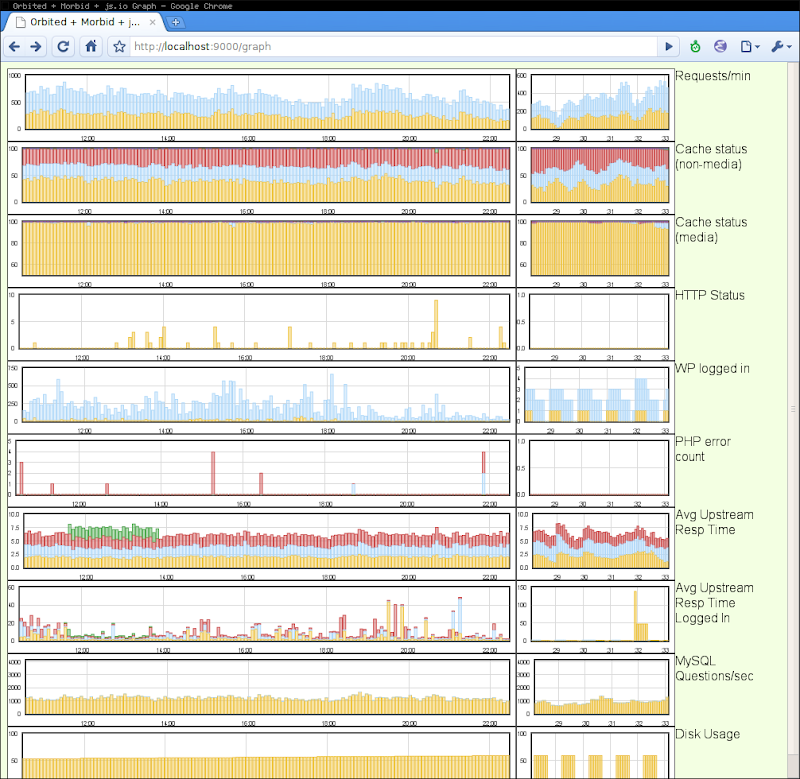
Live demo: http://184.73.64.212:9000/graph
(takes 5 seconds to update right-hand side plots, 5 minutes to update left-hand side plots)
What does it do?
- Streams data from remote servers (e.g. Nginx log files)
- Stores data to MongoDB
- Queries MongoDB for interesting analytics (e.g. cache hit rate, avg upstream resp time)
- Plots analytics data in the browser in real-time
What is it built with?
- Python
- MongoDB
- Orbited, Stomp, Twisted, js.io
- jQuery, Flot
Why MongoDB?
- Document-oriented, schemaless
- Capped collections
- Fast enough for the problem
- @parand seems to like it
References
Modules
- sources - classes for getting data from various sources
- parsers - classes for parsing various formats of data
- analyzers - classes for querying MongoDB for interesting information
- reportgenerators - a class which assembles data for display in a browser
- [executive modules] - two modules that run everything
sources module
Starts a subprocess and runs a ssh command to get data from a remote server [ sources.py]
from subprocess import Popen, PIPE, STDOUT
class SourceBase(object):
def start_stream(self):
self._assemble_ssh_command()
self.p = Popen(self.ssh_cmd, shell=True, stdout=PIPE, stderr=STDOUT)
def _assemble_ssh_command(self):
"""Use the dict, self.ssh_params and return the ssh command to run
"""
def get_line(self):
"""Use self.p.stdout.readline() to get a line of data
"""
def filter(self, line):
"""Return the line after optionally altering the line
"""
class SourceLog(SourceBase):
def __init__(self, ssh_params, filepath, encoding='utf-8'):
self.ssh_params = ssh_params
self.encoding = encoding
self.cmd = 'tail --follow=name %s' % filepath
parsers module
Use regular expressions to parse data (e.g. from a log file) [ parsers.py]
class BaseParser(object):
@classmethod
def parse_line(cls, line):
"""Parse one line of data using the regex pattern, cls.pattern
Return the data as a dict
"""
@classmethod
def convert_time(cls, time_str):
"""Convert date string to datetime object
"""
@classmethod
def post_process(cls, data):
"""Return optionally modified data
"""
class NginxCacheParser(BaseParser):
date_format = "%d/%b/%Y:%H:%M:%S"
pattern = ' '.join([
r'\*\*\*(?P<time>\S+ -\d{4})',
r'\[(?P<ip>[\d\.]+)\]',
r'(?P<status>HIT|MISS|EXPIRED|UPDATING|STALE|-)',
r'ups_ad: (?P<ups_ad>.*)',
r'ups_rt: (?P<ups_rt>.*)',
# ...
])
settings for the sources module
Parameters pertaining to the getting and storing of data [ settings.py]
from sources import SourceLog
from parsers import NginxCacheParser
NG_CACHE_COLL = 'ng_cache' # the name of the MongoDB collection
HOSTS = {
'us-ng1': {'host': 'us-ng1',
'hostname': '111.111.111.15',
'identityfile': '/home/saltycrane/sshkeys/myprivatekey',
'user': 'myusername',
},
# ...
}
SOURCES_SETTINGS = [
{'source': (SourceLog, {'ssh_params': HOSTS['us-ng1'], 'filepath': '/var/log/nginx/cache.log', 'encoding': 'latin-1',}),
'parser': NginxCacheParser,
'collection': NG_CACHE_COLL,
},
{'source': (SourceLog, {'ssh_params': HOSTS['us-ng2'], 'filepath': '/var/log/nginx/cache.log', 'encoding': 'latin-1',}),
'parser': NginxCacheParser,
'collection': NG_CACHE_COLL,
},
# ...
]
sourceexecutive module
Executive which gets data, parses it, and stores it to MongoDB [ sourceexecutive.py]
class SourceExecutive(object):
def __init__(self, settings):
self.collection = settings['collection']
self.parser = settings['parser']
self.source_class = settings['source'][0]
self.kwargs = settings['source'][1]
def start(self):
self.start_source_stream()
self.connect_to_mongo()
self.store_data()
def start_source_stream(self):
self.source = self.source_class(**self.kwargs)
self.source.start_stream()
def connect_to_mongo(self):
"""Connect to the MongoDB collection, self.collection
"""
def store_data(self):
while True:
line = self.source.get_line()
data = self.parser.parse_line(line)
self.mongo.insert(data)
sourceexecutive module (cont'd)
from settings import SOURCES_SETTINGS
for ss in SOURCES_SETTINGS:
s = SourceExecutive(settings)
s.start()
analyzers module
This class is used to query MongoDB for the average upstream response time grouped by upstream server. [ analyzers.py]
class AvgUpstreamResponseTimePerServerLoggedIn(object):
def __init__(self, mongo_collection, logged_in):
self.mongo = mongo_collection
self.logged_in = logged_in
def run(self, time_limit):
self.mongo.ensure_index([('time', ASCENDING), ('ups_rt', ASCENDING),
('ups_ad', ASCENDING), ('wp_login', ASCENDING), ])
result = self.mongo.group(
key=['ups_ad'],
condition={'time': {'$gt': time_limit[0], '$lt': time_limit[1]},
'ups_rt': {'$ne': '-'},
'wp_login': re.compile(self.logged_in),
},
initial={'count': 0, 'total': 0},
reduce=textwrap.dedent('''
function(doc, out) {
out.count++;
out.total += parseFloat(doc.ups_rt);
}'''),
finalize='function(out) {out.avg = out.total / out.count}',
)
result = sorted(result, key=lambda item: item['ups_ad'])
self.data = [r['avg'] for r in result]
reportgenerators module
Assemble a timeline of datapoints to send to the browser for plotting [ reportgenerators.py]
class FlotReportGenerator(object):
def __init__(self, settings, index, processed_collection):
"""Set attributes to parameters from the settings module and connect to MongoDB
"""
def connect_to_mongo(self):
"""Connect to the MongoDB collection for storing history data
"""
def run(self):
"""Generate all the data to be passed to flot
"""
self.create_metadata()
self.calc_window_endpoints()
self.run_analyzers_for_all_groups()
self.write_datapoint_to_mongodb()
self.get_and_assemble_history_data_for_flot()
self.assemble_current_datapoints()
self.prepare_output_data()
def create_metadata(self):
"""Assemble metadata data structures to send to the web frontend
"""
def calc_window_endpoints(self):
"""Calculate the window start and end points to be passed to each analyzer
"""
reportgenerators module (cont'd)
# class FlotReportGenerator(object):
# continued...
def run_analyzers_for_all_groups(self):
"""Loop through the list of groups (plots) to create and generate
datapoints
"""
def write_datapoint_to_mongodb(self):
"""Write datapoint data structure to mongoDB
"""
def get_and_assemble_history_data_for_flot(self):
"""Get history data from mongoDB and assemble it for transmission to a
flot stacked bar chart
"""
def assemble_current_datapoints(self):
"""Assemble a data structure of all the data points for the current
time formatted according to self.groups[groupname]['format']
"""
def prepare_output_data(self):
"""Assign all data to a single data structure, self.out
"""
settings for analysis / report generation
Parameters pertaining to analyzing the data [ settings.py]
from analyzers import AvgUpstreamResponseTimePerServerLoggedIn
PLOT_SET = {
'cache0': {
'label': 'Cache status (non-media)',
'format': '%.1f%%',
'collection': NG_CACHE_COLL,
'flot_options': {'yaxis': {'max': 100, }, },
'analyzers': [
(CacheStatus, {'status': 'HIT', 'media': '0'}),
(CacheStatus, {'status': 'MISS', 'media': '0'}),
(CacheStatus, {'status': 'EXPIRED', 'media': '0'}),
(CacheStatus, {'status': 'UPDATING', 'media': '0'}),
(CacheStatus, {'status': 'STALE', 'media': '0'}),
],
},
'aurt': {
'label': 'Avg Upstream Resp Time',
'format': '%.2f',
'collection': NG_CACHE_COLL,
'analyzers': [
(AvgUpstreamResponseTimePerServerLoggedIn,
{'logged_in': r'^\s*$', }),
],
},
# ...
}
settings for analysis / report generation (cont'd)
ANALYSIS_SETTINGS = {
'channel_name': '/topic/graph',
'time_periods': [
{'interval': 5 * 60, # in seconds
'history_length': 144, # number of processed data points to save
'default_window_length': 5 * 60 + 5, # in seconds
'default_flot_options': {
'series': {'stack': 0,
'bars': {'show': True,
'barWidth': (5 * 60) * (0.8 * 1000),
'lineWidth': 1, }, },
'xaxis': {'mode': "time",
'timeformat': "%H:%M",
'labelWidth': 20,
'labelHeight': 8,
},
'yaxis': {'min': 0,
},
},
'groups': PLOT_SET,
},
# ...
],
}
analyzerexecutive module
Queries MongoDB, assembles data, and sends data to the browser. [ analyzerexecutive.py]
from stompservice import StompClientFactory
from twisted.internet import reactor
from twisted.internet.task import LoopingCall
from reportgenerators import FlotReportGenerator
from settings import ANALYSIS_SETTINGS
class AnalyzerExecutive(StompClientFactory):
def __init__(self, settings):
self.channel_name = settings['channel_name']
self.time_periods = settings['time_periods']
self.intervals = []
self.report_generators = []
self.instantiate_report_generators()
def instantiate_report_generators(self):
"""Do this once for each report generator because we want to connect
to mongoDB only once
"""
for i, settings in enumerate(self.time_periods):
processed_collection = 'processed_%d' % i
rg = FlotReportGenerator(settings, i, processed_collection)
self.intervals.append(settings['interval'])
self.report_generators.append(rg)
analyzerexecutive module (cont'd)
# class AnalyzerExecutive(StompClientFactory):
# continued...
def recv_connected(self, msg):
"""Start infinite loops for each of the time periods
"""
for i in range(len(self.report_generators)):
self.timer = LoopingCall(self.generate_and_send_data, i)
self.timer.start(self.intervals[i])
def generate_and_send_data(self, i):
"""This is called every loop
"""
self.report_generators[i].run()
jsondata = json.dumps(self.report_generators[i].out)
self.send(self.channel_name, jsondata)
ae = AnalyzerExecutive(ANALYSIS_SETTINGS)
reactor.connectTCP('localhost', 61613, ae)
reactor.run()
Plans
- Use WebSockets instead of Orbited, Stomp, and js.io
- Make settings.py into a YAML file
- Considering Protovis instead of Flot
- Add plot legends
- Clean up process termination